Scaling Sidekiq is difficult when paired with Redis. The hurdle arises from the complexity of Redis’ horizontal scaling style:
- Redis is most commonly single-threaded, not able to completely make the most of trendy multi-core servers.
- Alternatively, it’s discouraged to make use of Redis Cluster for Sidekiq, as detailed right here.
This catch 22 situation steadily ends up in throughput bottlenecks when the use of Sidekiq with Redis. We now have optimized Dragonfly, a contemporary multi-threaded drop-in substitute for Redis that can be utilized as a backend knowledge retailer for Sidekiq, to handle those scaling demanding situations. With out additional ado, let’s dig into how we did this.
Sidekiq Evaluation
Sidekiq is an effective background process processing device for Ruby. Software customers publish paintings (jobs), which Sidekiq executes asynchronously. Sidekiq decouples execution and garage properly by means of the use of Redis because the backend knowledge retailer. Sidekiq shoppers act as manufacturers of labor that push pieces that describe that paintings (process kind, arguments, and many others.) right into a Redis Checklist knowledge construction. The Sidekiq server iteratively consumes the pieces one at a time and executes them. When there is not any process left, Sidekiq blocks and waits for extra process pieces to transform to be had. That is accomplished internally with the BRPOP command.
Scalability and Bottlenecks
At the Sidekiq consumer aspect, we most often apply a couple of shoppers sending jobs. That is anticipated, since one of the crucial major causes for incorporating a background processing device is to dump paintings from user-facing products and services and procedure it asynchronously.
Let’s center of attention at the Sidekiq server (or execution) aspect, with the backend knowledge retailer being Redis. Sidekiq can spawn a couple of processes since Ruby’s international interpreter lock (GIL) prevents code from operating in parallel. Sure, code can run similtaneously, however this isn’t to be perplexed with parallelism. And be aware right here that the principle use of multi-threaded Sidekiq processes is basically to permit multiplexing of IO. JRuby is an exception, however it is also esoteric, since JRuby isn’t at all times to be had or utilized by Sidekiq customers and a extra normal way is preferable. In a nutshell, extra processes result in extra requests, and parallel process execution achieves upper throughput. The one explanation why we opted for a couple of processes for benchmarking and optimization is that we assumed that simple Ruby was once extra related to a bigger target market. And each approaches (JRuby threads vs. a couple of Ruby processes) paintings similarly neatly.
As for the backend retailer, we’ve Redis, which is single-threaded from the viewpoint of command execution. Scaling Redis can also be performed by means of making a Redis Cluster. Sadly, this comes with its personal set of boundaries corresponding to operational complexity, and no longer having the ability to ensure high-performance transactions. Thus, as discussed above, it’s discouraged to make use of Redis Cluster for Sidekiq by means of the Sidekiq maintainers themselves. The important thing takeaway here’s that the extra you get started scaling Sidekiq, the extra force you building up on Redis, which someday inevitably turns into the principle bottleneck within the total throughput (jobs/sec).
Now you may well be questioning why hassle with all of those main points; it is all about integration, proper? Nope! Integration is the straightforward section. Dragonfly is Redis API-compatible, so switching from Redis to Dragonfly is as simple as shutting down the previous and beginning the latter. The main points transform very important when functionality is desired, and as you’ll see later, Dragonfly’s structure allows Sidekiq to scale to a brand new degree. This adventure is all about a number of the optimizations that unlocked one of the most functionality bottlenecks alongside the best way.
Benchmark Preparation
We based totally our paintings at the benchmark discovered right here. The benchmark spawns a unmarried Sidekiq procedure, and it pushes N no-op jobs to the paintings queue. It then begins measuring how a lot time it took to fetch and procedure the ones jobs. For the reason that process merchandise itself is a no-op operation, we successfully measure IO, this is, how a lot throughput (jobs/sec) Sidekiq can pull out of the backend knowledge retailer sooner than it turns into a bottleneck.
Our way comprises the next adjustments:
- Upload beef up to Sidekiq’s benchmark to paintings with a couple of Sidekiq processes. This permits us to scale the benchmark and show off the proscribing components of upper throughput.
- We used an AWS
c5.4xlargeexample to run the backend knowledge retailer (Redis or Dragonfly). - We deliberately used a extra tough device (AWS
c5a.24xlargewith 96 cores) to run the benchmark. This guarantees that Sidekiq by no means turns into the bottleneck, as it may possibly pull as many roles as Dragonfly can ship. - We used one queue in keeping with Sidekiq procedure.
- We deliberately do not measure the time shoppers used to push the information (i.e., including jobs to the queue), as a result of pushing or popping from the queue boils right down to the similar amendment operations within the knowledge retailer.
Benchmark Redis
First, we run the benchmark with Sidekiq working on Redis, with 96 Sidekiq processes and 1 million jobs in keeping with queue. The desk beneath summarizes the consequences:
| Queues | General Jobs | Redis Throughput (Jobs/Sec) |
|---|---|---|
| 1 | 1M | 137,516 |
| 2 | 2M | 142,873 |
| 8 | 8M | 143,420 |
As you’ll be able to see, there’s a arduous restrict of kind of 140k jobs/sec. The reason being that, as mentioned above, Redis runs most commonly on a unmarried thread. So even though we build up the collection of queues, we nonetheless use 1/Nth of the to be had processing energy, with N because the collection of threads outlined by means of --proactor_threads for Dragonfly.
Benchmark Dragonfly Baseline
Preferably, we want to scale Dragonfly linearly to the collection of threads N to be had. Even supposing unimaginable in apply because of the inherent abstraction price of distributing paintings and different transactional traits, the nearer we’re to that quantity, the happier we will have to be. This quantity is most commonly our theoretical most, as though one thread can ship X jobs, then N threads will have to ship X * N jobs.
Now let’s run the similar benchmark with Dragonfly configured within the following other ways. Word that we additionally fit the collection of Dragonfly threads to the collection of queues.
- With
--proactor_threads=1which limits Dragonfly to operating on a unmarried thread, similar to Redis. - With
--proactor_threads=2which runs Dragonfly on 2 threads. - With
--proactor_threads=8which runs Dragonfly on 8 threads.
The desk beneath summarizes the consequences:
| Queues & Dragonfly Threads | General Jobs | Dragonfly Throughput (Jobs/Sec) |
|---|---|---|
| 1 | 1M | 50,776 (Baseline) |
| 2 | 2M | 11,2647 |
| 8 | 8M | 148,646 |
That is our baseline. Unmarried-threaded Dragonfly delivers nearly part of Redis throughput, and the configuration with 8 threads is as rapid as Redis, which is far beneath our expectancies. We used the htop command to look at the usage of every CPU core, and the very first thing we spotted was once that the burden was once no longer similarly unfold a number of the to be had cores. One of the vital 8 CPU cores have been actually underutilized, whilst others have been loaded at greater than 90% capability.
To grasp why, we first wish to dive a little bit bit into Dragonfly internals. To totally leverage {hardware} assets, Dragonfly makes use of a shared-nothing structure and splits its keyspace into shards. Every shard is owned by means of a unmarried Dragonfly thread, and get admission to to the information is coordinated by way of our transactional framework. For our use case, the information are the contents of every of the queues. To come to a decision which thread owns a queue, Dragonfly hashes the identify of the queue and modulo it by means of the collection of threads.
The primary remark above within the benchmark is that the a couple of queues weren’t frivolously unfold a number of the to be had shards, successfully lowering the stage of parallelism within the device. Merely put, some Dragonfly threads have been a lot busier than others.
Optimization With Spherical-Robin Load Balancing
To reconcile with this, we fairly configure Dragonfly otherwise with the server flag --shard_round_robin_prefix. With this flag, keys (i.e., names of the queues) with a definite prefix are allotted in a round-robin model. This successfully acts as a load balancer, spreading the queues rather a number of the to be had shard threads. Operating the similar benchmarks with the above setup were given us:
| Queues & Dragonfly Threads | General Jobs | Dragonfly Throughput (Jobs/Sec) |
|---|---|---|
| 1 | 1M | 50,776 |
| 2 | 2M | 113,788 |
| 8 | 8M | 320,377 (Spherical-Robin) |
The primary benchmark with --proactor_threads=1 for Dragonfly isn’t truly affected since it is single-threaded. The similar applies to the second one benchmark as a result of each queues finally end up on two other shards anyway. On the other hand, for the 3rd benchmark with --proactor_threads=8 and --shard_round_robin_prefix for Dragonfly, the throughput was once larger by means of 2x from the former benchmark. This is the htop output with round-robin load balancing:

The per-core saturation is a little bit bit extra balanced, however what drives the functionality spice up is the higher stage of parallelism. This turns into much more obvious while you scale on better machines with--proactor_threads set to 16, 32, 64, 128, and many others., as increasingly queues finally end up at the identical shard thread, seriously halting parallelization.
That is surely an growth from the former run, however we aren’t slightly there but as a result of each the one and two-threaded variants are nonetheless considerably slower. What are the opposite low-hanging culmination?
Optimization With Hops and Transactions
One of the most key insights in understanding the bottlenecks was once within the implementation of multi-key blockading instructions like BRPOP. Consider after I talked in brief above about shard threads and the transactional framework in Dragonfly? Smartly, a multi-key command would possibly get admission to knowledge on other shard threads, and this motion is carried out by means of executing callbacks on them. A unmarried dispatch set of the ones callbacks is named a hop, and a transaction can also be both multi-hop or single-hop. Multi-hop transactions are usually extra concerned as a result of they require filing paintings to other shard threads iteratively, and there’s latency when distributing paintings over and protecting locks related to keys longer. Within the period in-between, single-hop transactions have positive optimizations integrated.
Circling again to the blockading instructions, BRPOP is applied as a multi-hop transaction. The overall case (with out blockading) is that we do a unmarried hop to the shard threads that include the asked queues (i.e., BRPOP queue_01 queue_02) and take a look at if they’re non-empty. And that is how the primary hop seems:
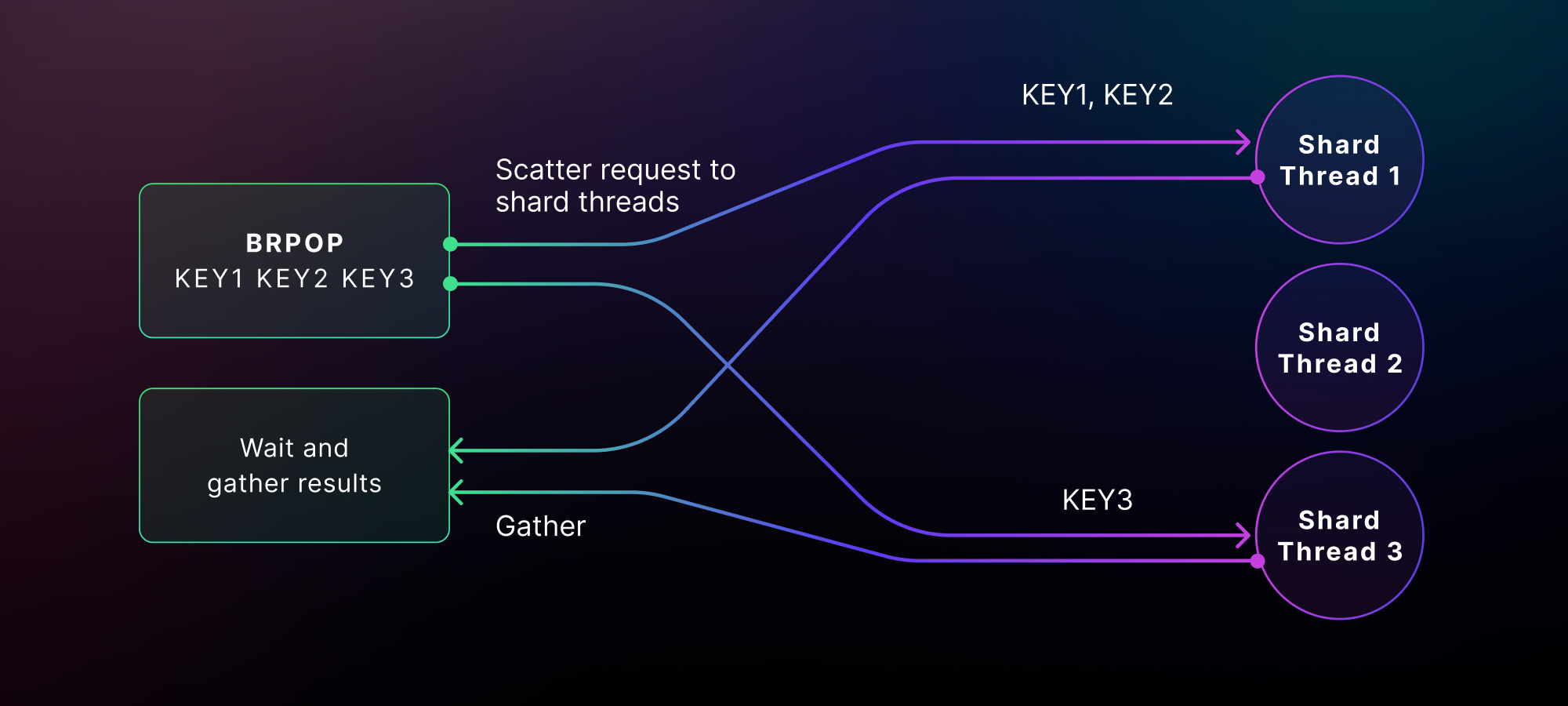
Since BRPOP takes a couple of queue names as enter, it exams they all however handiest pops one part at a time from those queues. Dragonfly then filters and decreases the consequences to just one by means of discovering the primary queue this is non-empty. Finally, Dragonfly plays an additional hop to fetch the thing from the queue we picked. The whole dance is thus a multi-hop transaction, which looks as if beneath:
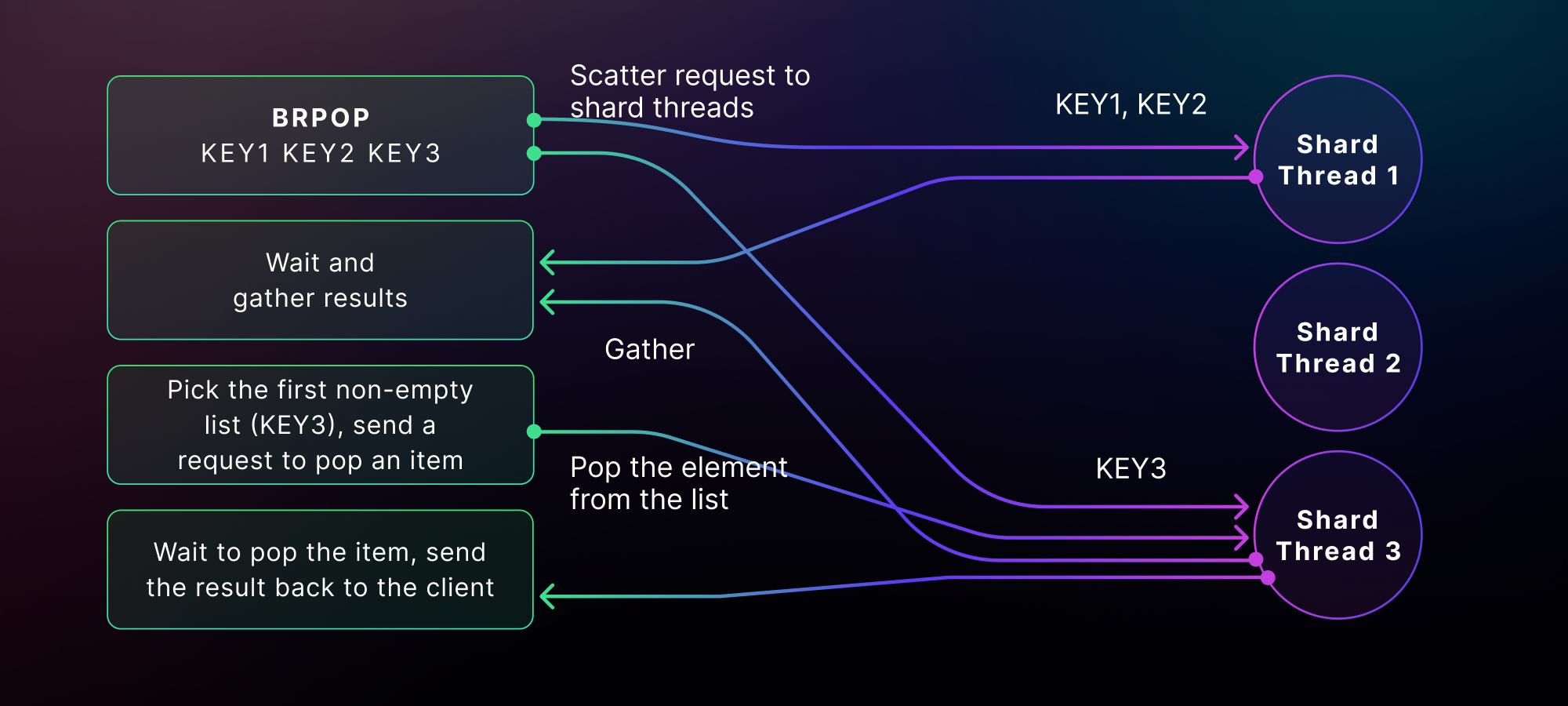
So, are we able to do higher for the Sidekiq-specific use case with the BRPOP command?
Realize the get admission to trend of Sidekiq processes. They at all times eat from the similar unmarried queue. First, there’s at all times a unmarried queue this is used to name BRPOP. 2nd, the queue is at all times non-empty, and lets run opportunistically, which means that we will squash “polling for the queue to be non-empty” and “fetching the thing from the queue” right into a unmarried hop. And when this does not occur (i.e., the queue is empty and blockading is wanted), we fall again to the former two-hop dance.
We presented this single-hop, single-shard optimization for blockading instructions and added a brand new configuration flag --singlehop_blocking which defaults to true. The most important advantage of this optimization, but even so the relief of hops, is that now blockading transactions can each be inline and fast. The previous is when the transaction runs at the identical shard thread as the only the command would hop to. The latter is when there aren’t any conflicting transactions; this is, no different transaction holds locks to the similar keys. When that is true, we’ve an optimization in position that just about bypasses the transactional framework altogether (we do not publish paintings or gain any locks) and executes the command eagerly, bettering latency and function considerably. This works as a result of just one fiber at a time can also be energetic on a unmarried shard thread, and that is vital:
- Assuming there aren’t any different energetic transactions that grasp locks to the similar keys
- For the ones of you who have no idea, a fiber is a light-weight thread, and it handiest exists in consumer area. Fibers will have to come to a decision when to preempt, and after they do, they droop themselves and move keep an eye on to the scheduler. The scheduler switches and turns on the following fiber with the very best precedence. Due to this fact, there can also be loads of fibers in keeping with shard thread, however just one can also be energetic at any time. This mechanism promises that the fiber would possibly not get interrupted by means of some other transaction, and this permits us to avoid the transactional framework altogether with out violating any of our transactional promises.
The good information is that this is applicable robotically to the get admission to patterns of our use case, and subsequently a large number of the BRPOP instructions finally end up as fast transactions. This boosts our effects properly, with 488k jobs/sec for 8 queues and eight Dragonfly threads.
| Queues & Dragonfly Threads | General Jobs | Throughput (Jobs/Sec) |
|---|---|---|
| 1 | 1M | 115,528 |
| 2 | 2M | 241,259 |
| 8 | 8M | 487,781 (Spherical-Robin & Unmarried-Hop) |
Word that transactional statistics from the server aspect can also be accessed by way of the INFO ALL command. Should you run the other steps with INFO ALL, you’ll understand an enormous exchange within the underline transaction sorts.
Conclusion
On this article, we mentioned the mixing of Sidekiq with Dragonfly and the optimizations we presented to extend the whole throughput. To run Sidekiq with Dragonfly in only a few mins, you’ll be able to practice the directions on this new Sidekiq integration information.
I imagine that it is truly rewarding to paintings on a device this is able to saturating the {hardware}. What is much more rewarding is the method of optimizing the other use circumstances that stand up alongside the best way. You understand you had a just right day while you spot and minimize out the ones low-hanging culmination, and also you apply in real-time your device revving like a 90’s Shelby. We noticed a pleasing ~9.6x build up from our Dragonfly baseline (scaled from 51k to 488k) and a ~3.5x spice up in comparison to Redis (140k vs. 488k). Are we able to do higher? Perhaps, however that may be a subject matter for a long term weblog put up.
Appendix: Benchmark Setup and Main points
For individuals who wish to reproduce the benchmark effects, listed below are the main points:
- We used an AWS
c5.4xlargeexample for operating Dragonfly or Redis. - We used an AWS
c5a.24xlargeexample for operating Sidekiq. - Every queue was once stuffed with 1 million no-op jobs. So for 8 queues, we had 8 million jobs in general.
- The working device was once Ubuntu v22.04 with Kernel model
6.2.0-1017-aws. - To run Dragonfly, we used the next command:
$> ./dragonfly --proactor_threads=8 # 1, 2, 8
--shard_round_robin_prefix="queue" # with the round-robin load balancing- To run the benchmark, we used the command beneath. Word that we matched the quantity queues with the collection of Dragonfly threads.
$> RUBY_YJIT_ENABLE=1 PROCESSES=96 QUEUES=1 THREADS=10 ./multi_queue_bench