Massive Language fashions (LLMs) are used for ingenious duties comparable to tale writing, poetry, and script writing for performs. There are a number of GPT-based wrapper equipment for promoting slogan introduction, producing plot traces, and tune compositions. Let’s discover how one can use LLMs to spot analysis gaps in a box and leverage the information of alternative fields to encourage new concepts.
Drawback Commentary
Researchers want inspiration when they’re caught on an issue. It is common for researchers to get fixated on a specific speculation or means. The huge quantity of knowledge can also be overwhelming. This can be a fight in itself to sift throughout the data and determine a possible new trail. Interdisciplinary collaboration is regularly difficult with researchers on each side now not aware of the jargon of the 2 fields.
The Resolution
We will be able to construct an answer the usage of Retrieval Augmented Era (RAG)
Retrieval: By means of construction a vector database of all analysis articles, we will be able to fetch related articles from two fields.
Era: After we retrieve the highest articles related to the 2 fields, we will be able to then construct a instructed and ask the Massive Language type to spot gaps in analysis box A and use articles from box B to get a hold of answers.
Since we’re forcing a box B, hallucination is anticipated. Hallucination is a now not worm. This can be a characteristic since we’re selling inspiration.
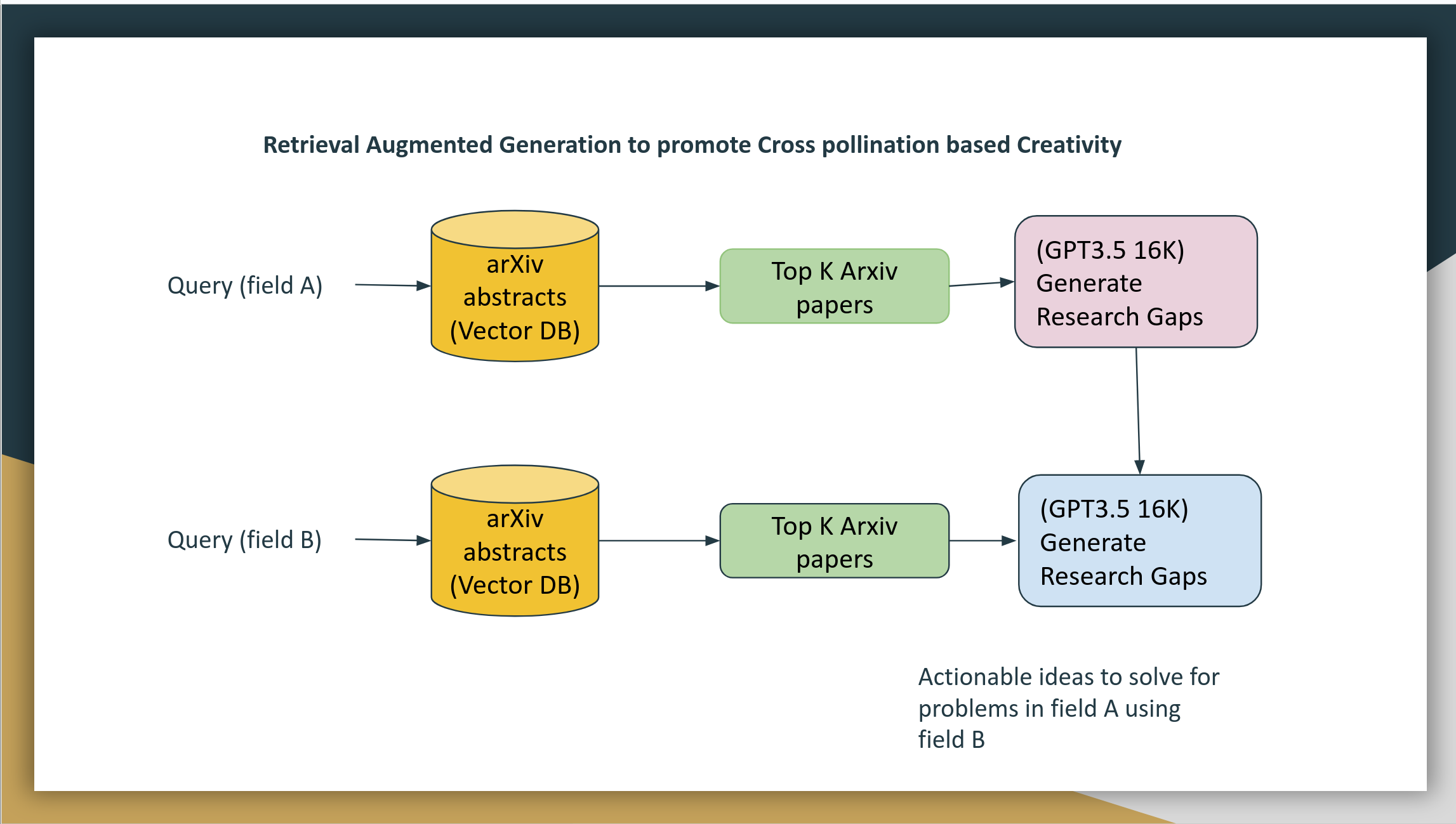
Determine: Machine design diagram of RAG gadget for cross-pollination
Construction the Vector Index
prerequisite: Python 3.9, pip
1. pip set up -r necessities.txt
numpy==1.25.2
torch==2.0.1
annoy==1.17.3
langchain==0.0.237
sentence-transformers==2.2.22. Kaggle arXiv dataset
Create a kaggle account and obtain the arXiv dataset. After downloading, unzip the report to discover a JSON report. This can be a restricted dataset with a identify, summary, writer, and submission date.
3. Construct an annoy index the usage of Sentence BERT
import json
from sentence_transformers import SentenceTransformer, util
import numpy as np
import torch
import time
from annoy import AnnoyIndex
file_name = "arxiv-metadata-oai-snapshot.json"
'''
Preprocess the knowledge and construct a listing
'''
def preprocess(trail):
records = []
beginning = time.time()
with open(trail,'r') as f:
for line in f:
records.append(json.a lot(line))
beginning = time.time()
sents = []
for i in vary(len(records)):
sents.append(records[i]['title']+'[SEP]'+records[i]['abstract'])
finish = time.time()
print("Time taken: ",end-start)
go back sents
'''
Use Sentence BERT Specter embedding to construct a numpy array
'''
def generate_embeddings(sents,type):
embeddings = type.encode(sents,batch_size=400,show_progress_bar=True,instrument="cuda",convert_to_numpy=True)
np.save("embeddings.npy",embeddings)
go back embeddings
'''
Generate an annoy index.
As an alternative of opting for angular as distance metric, different choices comparable to euclidean also are to be had
'''
def generate_annoy(embeddings):
n_trees = 256
embedding_size = 768
top_k_hits = 5
annoy_index = AnnoyIndex(embedding_size, 'angular')
for i in vary(len(embeddings)):
annoy_index.add_item(i, embeddings[i])
annoy_index.construct(n_trees)
annoy_index.save("vector_index.ann")
go back annoy_index
sents = preprocess(file_name)
type = SentenceTransformer('sentence-transformers/allenai-specter', instrument="cuda")
embeddings = generate_embeddings(sents,type)
annoy_index = generate_annoy(embeddings)if you’re working on GPU, alter batch measurement as it should be
Instructed 1 – Retrieve Analysis Gaps
Now that we have got constructed a vector index wanted for retrieval, step one is to retrieve the analysis gaps of box A
- Question vector index (annoy) to retrieve best Ok arXiv articles
- Construct a instructed in line with the identify + summary
- Use a big language type to retrieve analysis gaps
Our choices for LLMs with massive token lengths come with
- GPT 3.5 with 16K token duration
- Yi 34B type with 200K token duration
- Anthropic Claude with 100K token duration
Token duration issues right here since we’re going to ask LLM to generate analysis gaps.
Set Up Sentence Bert, Load Annoy, Open AI Credential
## index from Annoy
an = generate_annoy(“
llm = OpenAI(openai_api_key=open_ai_key, model_name= “gpt-3.5-turbo-16k”)” data-lang=”textual content/x-python”>
type = SentenceTransformer('sentence-transformers/allenai-specter', instrument="cpu")
OPENAI_API_KEY = getpass("Please input your OPEN AI API KEY to proceed:")
## load the OPENAI LLM type
open_ai_key = OPENAI_API_KEY
sents_from_path = preprocess("<Trail for your arxiv.json>")
## index from Annoy
an = generate_annoy("<identify of the index.ann>")
llm = OpenAI(openai_api_key=open_ai_key, model_name= "gpt-3.5-turbo-16k")
Strategies for Retrieving Best Ok Articles and Metadata
def seek(question,annoy_index,type, topK):
query_embedding = type.encode(question,convert_to_numpy=True)
tokens = question.strip().break up()
hit_dict = {}
hits = annoy_index.get_nns_by_vector(query_embedding, topK, include_distances=True)
go back [hits, hits]
def collect_results(hits,sents, trail, prefix=""):
reaction = ""
for i in vary(len(hits[0])):
reaction += "outcome " + prefix + str(i) + "n"
reaction += "Identify:" + sents[hits[0][i]].break up('[SEP]')[0] + "n"
reaction += "Summary: " + sents[hits[0][i]].break up('[SEP]')[1] + "n"
go back reactionAssemble the Instructed for Figuring out Analysis Gaps
fieldA = enter("Describe the sphere (or subfield) as a question:")
question = fieldA
reaction = collect_results(seek(question,an,type,30),sents_from_path1, path1)
template = """ Take a deep breath.
You're a researcher within the FIELD of {question}. You're tasked with figuring out analysis gaps and alternatives. Person entered the FIELD. The TOP ARTICLES from the quest engine are {reaction}. Analyze the effects and practice the directions under to spot analysis gaps within the box of {question}.
TASK DESCRIPTION
On this process, your purpose is to acknowledge spaces inside of a specified FIELD the place additional analysis is wanted.
By means of inspecting present literature and TOP ARTICLES , records, and possibly the trajectories of ongoing analysis, the AI can assist indicate subjects or questions that have not been adequately explored or resolved. This is very important for advancing wisdom and discovering new instructions that might result in vital discoveries or trends
As an example, imagine the area of renewable power. one may analyze an unlimited collection of analysis papers, patents, and ongoing tasks on this area. It will then determine that whilst there may be ample analysis on sun and wind power, there may well be a relative loss of analysis on harnessing tidal power or integrating various kinds of renewable power methods for extra constant energy technology.
By means of figuring out those analysis gaps, you're going to assisint in pinpointing spaces the place researchers can center of attention their efforts to probably make novel contributions. Additionally, it could actually assist investment companies and establishments to direct assets and improve in opposition to those recognized spaces of alternative, fostering developments that may differently be overpassed.
INSTRUCTIONS:
1. Analyze each and every article returned by means of the quest engine.
2. Establish the analysis gaps and alternatives for each and every article
3. Summarize the analysis gaps and alternatives within the box of {question} throughout ARTICLES. The analysis hole will have to BE GROUNDED at the articles returned by means of the quest engine.
3. Establish an orthogonal box and generate key phrase to get articles from that box that may clear up the analysis gaps.
4. Establish a comparable box and generate key phrase to get articles from that box that may clear up the analysis gaps
5. Generate a JSON Reaction that STRICTLY practice the TYPESCRIPT SCHEMA of sophistication Reaction under
6. Output MUST BE a JSON with the next fields within the SCHEMA.
SCHEMA:
magnificence Reaction:
orthogonal_field: String
keyword_orthogonal_field: String
related_field: String
keyword_related_field: String
research_gaps: String
"""
instructed = PromptTemplate(template=template, input_variables=["query", "response"])
llm_chain = LLMChain(instructed=instructed, llm=llm)
output = ""
check out:
output = llm_chain.run({'question': question, 'reaction':reaction})
aside from Exception as e:
print (e)
We think the reaction to be in JSON layout. On occasion, LLM would possibly not practice the directions to the dot and motive JSON parsing problems.
Instructed 2- Retrieve Analysis Gaps
Now that we have got the analysis gaps from the JSON[“research_gaps”], we will be able to do a an identical retrieval of best papers from box B to get a hold of new concepts. The output of analysis gaps from instructed 1 is fed to instructed 2.
llm_response = json.a lot(output)
fieldB = enter("Input box B:")
orthogonal_field = fieldB
reaction = collect_results(seek(fieldB,an,type,30),sents_from_path1, path1)
research_gap = llm_response["research_gaps"]
## move pollination instructed
template = """ Take a deep breath.
You're a researcher within the FIELD1 of {question}. You're tasked with exploring concepts from some other FIELD2 of {orthogonal_field} and determine actionable concepts and attach the analysis gaps.
RESEARCH GAP: You're given the issue of {research_gap} within the FIELD1.
OPPORTUNITIES : You're advised the possible alternatives are {opportunies}
Seek Engine returned best articles from FIELD2 {reaction}.
Process description:
You're anticipated to spot actionable concepts from FIELD2 that may repair the analysis hole of FIELD1. Concepts will have to be grounded at the articles returned by means of the quest engine.
Instance 1: The appliance of ideas from physics to biology resulted in the improvement of magnetic resonance imaging (MRI) which is now a basic software in scientific diagnostics.
Instance 2: Ideas from the sphere of biology (e.g., evolutionary algorithms) had been carried out to computational and engineering duties to optimize answers in a way analogous to herbal variety.
Practice the directions under to spot actionable concepts from FIELD2 and attach the analysis gaps of FIELD1
INSTRUCTIONS:
1. Learn each and every article of FIELD2 from Seek engine reaction and determine actionable concepts that may repair the RESEARCH GAP of FIELD1
2. Summarize the actionable concepts within the box of FIELD2 that may repair the RESEARCH GAP of FIELD1
3. Generate a JSON Reaction that STRICTLY practice the TYPESCRIPT SCHEMA of sophistication Reaction under
4. Output MUST BE a JSON ARRAY with the next fields within the SCHEMA.
5. Actionable concept will have to be a sentence or a paragraph that may repair the analysis hole of FIELD1
5. Explanation why will have to be a sentence or a paragraph that explains why the actionable concept can repair the analysis hole of FIELD1 the usage of the information of FIELD2
6. GENERATE upto 10 ACTIONABLE IDEAS and atleast 3 ACTIONABLE IDEAS
SCHEMA:
Magnificence Reaction:
actionable_ideas: String
explanation why: String
"""
instructed = PromptTemplate(template=template, input_variables=["query", "orthogonal_field", "research_gap", "opportunies", "response"])
llm_chain = LLMChain(instructed=instructed, llm=llm)
check out:
output = llm_chain.run({'question': question, 'orthogonal_field':orthogonal_field, 'research_gap':research_gap, 'opportunies':opportunies, 'reaction':reaction})
print (output)
aside from Exception as e:
print (e)We’ve got adopted the “Chain of Concept” prompting with the preferred “Take a deep breath” method.
It’s also imaginable to let the LLM infer an adjoining or orthogonal box B as a substitute of the researcher enter box B.
Anecdotal Instance:
FieldA: City making plans and mobility
FieldB: Synthetic Intelligence
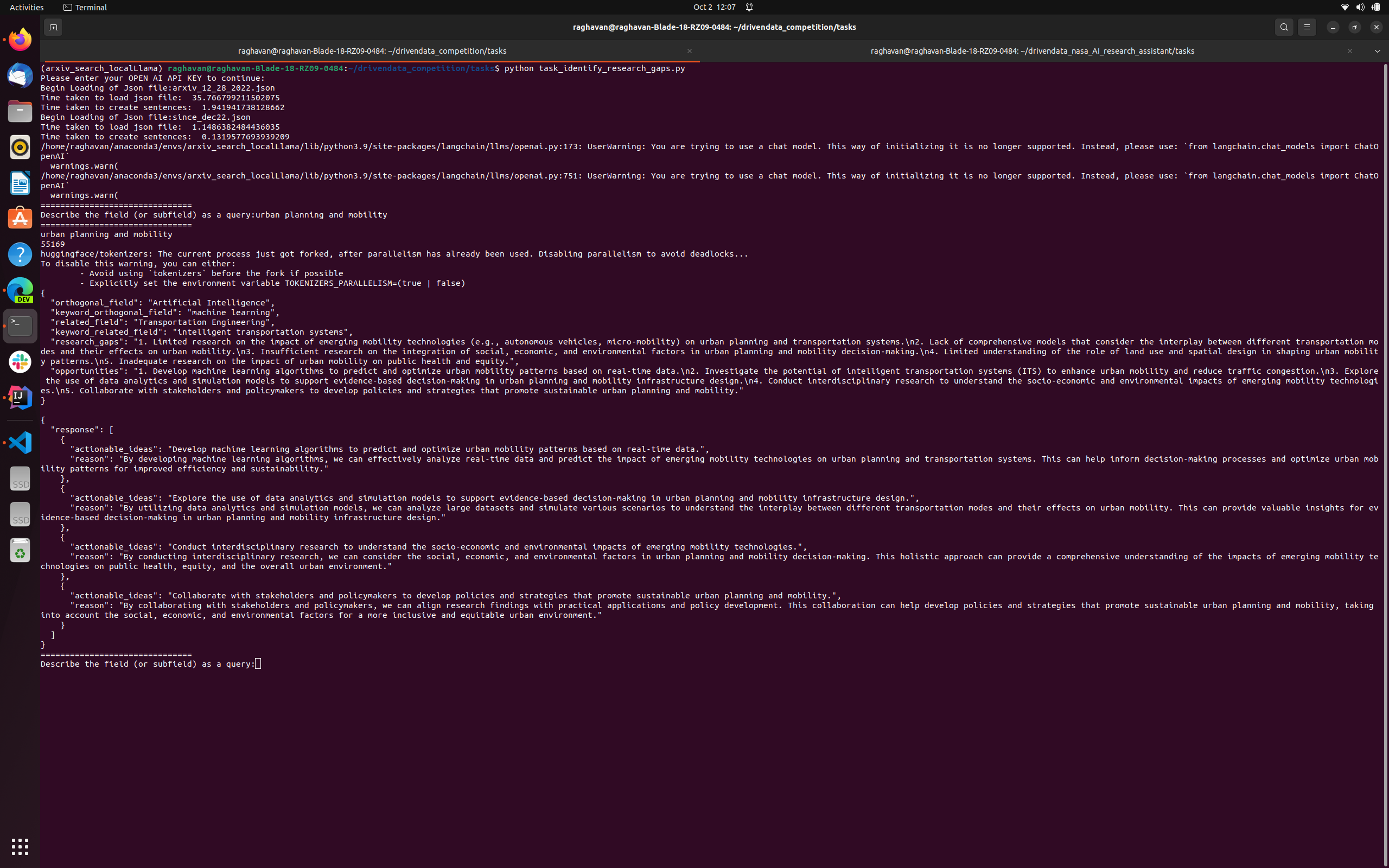
Person Member inputs “city making plans and mobility” Machine reads the highest articles from Arxiv and identifies the analysis gaps and alternatives additionally counsel an orthogonal box “Synthetic Intelligence”. It then mines articles from Synthetic Intelligence and proposes actionable concepts and causes to the researcher. This may function inspiration
1s actionable concept: “Increase ML algorithms to are expecting and optimize city mobility patterns the usage of real-time records”. This may remind us of Waze rerouting drivers founded on the right track
second actionable concept: “Discover using records analytics and simulation fashions to improve evidence-based decision-making in city making plans and mobility infrastructure design”
Whilst those concepts may well be really easy for one to discern if they have got an AI/ML background, they may well be a watch opener and inspiration for city making plans policymakers and not using a such background.
Conclusion
With an RAG resolution, researchers and policymakers can leverage massive language fashions and fasten the dots of unrelated fields, selling efficient cross-pollination. Hallucination is without a doubt an opportunity once we power two unrelated fields for cross-pollination however it’s no longer a worm however a characteristic for selling inspiration.
Footnote:
This text is in line with a couple of hackathon submissions at quite a lot of venues together with lablab.ai
Writer’s Profile