Metrics are an important a part of complicated allotted garage methods, corresponding to Apache Cassandra. It will be significant for an operator and a consumer to have get entry to to metrics on the OS, JVM, and alertness ranges to have complete keep an eye on over the knowledge this is being processed and to forestall emergencies ahead of they happen.
To make metrics out there, Cassandra closely is determined by the open-source Dropwizard Metrics library, which acts as a skeleton for each metrics illustration and garage. Metrics representations are supplied as Histogram, Timer, Meter, Gauge, and so on. categories for metric sorts, whilst garage makes use of MetricRegistry. The Dropwizard library makes it smooth to reveal the database internals via quite a lot of APIs, like JMX or REST, along with the sidecar development. Apache Casandra has a colourful ecosystem on this regard, as an example, you’ll be able to write your java-agent to export all information from the registry to the collectd Unix daemon. In conjunction, Cassandra’s digital tables, that are a somewhat contemporary building through the undertaking’s requirements (to be had since 4.0), have just a fraction of all of the metrics thus far, so do not give a complete view of inside processes and want to be progressed to rectify this.
My identify is Maxim Muzafarov, I am an Apache Ignite PMC member, an Apache Cassandra Committer and a tool engineer within the Open Supply Program Workplace at Aiven, a world open-source information platform corporate. I might love to let you know concerning the issues that I encountered whilst enforcing a brand new patch to “Divulge all desk metrics within the digital desk” and the demanding situations and problems which have been addressed to in the end make all metrics to be had via digital tables in order that customers can depend on them and question them performantly.
Review Metrics Structure
One of the vital problems we will be able to follow go with the flow seamlessly from how Dropwizard Metrics is used within the supply code and the restrictions of the library itself, so a phrase or two concerning the library’s structure is worth it.
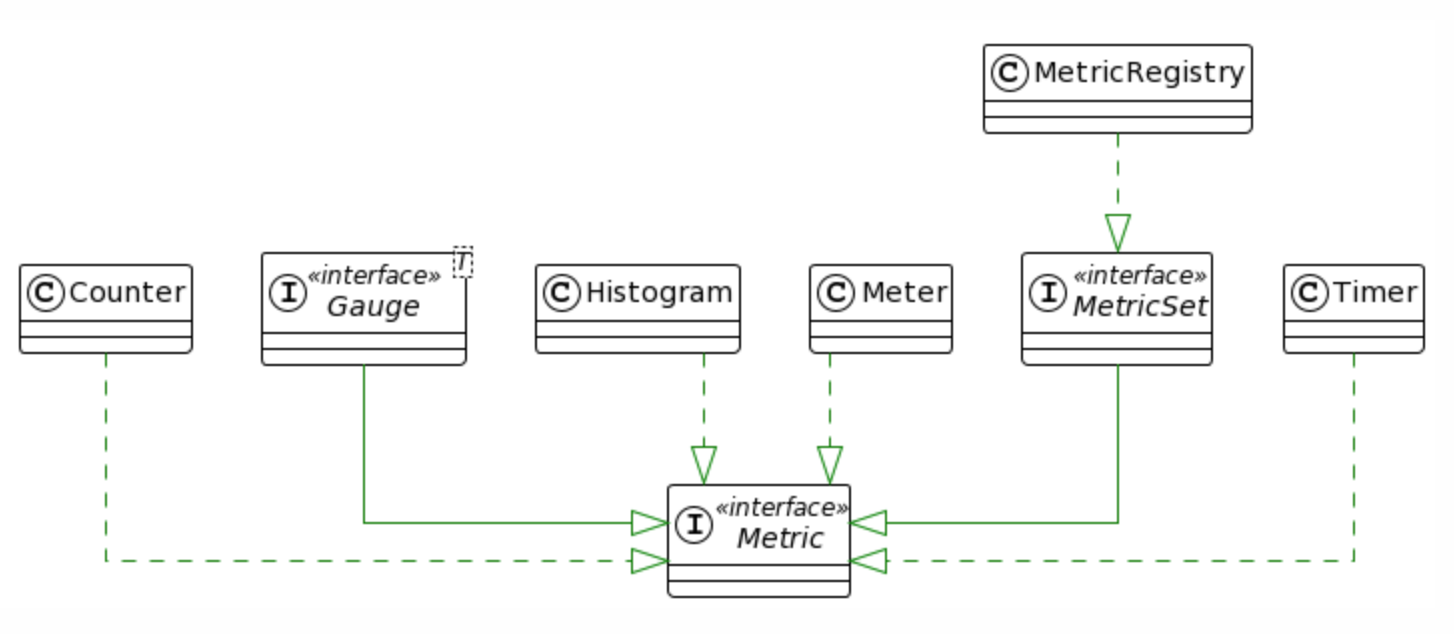
The start line for Dropwizard Metrics is the MetricRegistry, which is a collection of all of the metrics registered in Apache Cassandra. This registry makes use of a ConcurrentHashMap below the hood, with metric names as keys and cases of quite a lot of metric sorts as values. Apache Cassandra makes use of a singleton example of MetricRegistry, and because of this, we’ve got one international set of metrics for tracking. In consequence, the best way we assemble metric names is a very powerful, as those names are very important for filtering and figuring out the proper entities inside metric teams throughout CQL question execution. You are going to see beneath how this would possibly impact functionality.
On the other hand, in contrast to a well-liked selection like Prometheus, Dropwizard Metrics has some barriers. Specifically, it lacks label beef up, which is very helpful for evolving metric names and deprecating the previous ones to maintain backward compatibility (this factor is triumph over as a registering alias for a metric by means of the CassandraMetricsRegistry extension). It additionally tends to accomplish calculations at the server facet, which, if the tracking device is incorrectly configured, can impact node functionality and building up the entire GC force at the node. That is specifically true for Histograms in Apache Cassandra, which through design contain some heavy calculations in the course of the o.a.c.m.DecayingEstimatedHistogramReservoir throughout buckets of saved counters. Prometheus, however, exposes uncooked values.
CQL Metrics Reporter
Apache Cassandra 4.0 offered digital tables, which emulate get entry to to device data via the similar API used to get entry to and set up information saved as SSTables. This, in flip, signifies that we will be able to create a digital desk round an inside selection of information saved within the JVM heap (or off-heap) to constitute it as a desk, and the MetricRegistry is strictly a selection of metrics we intend to export. That is the place the idea that of the Dropwizard Metrics Reporter is available in, which I’ve carried out.
Necessities and Checking out
In apply, both the CQLReporter or a digital desk adapter, designed to export all metrics as digital tables, will have to beef up positive forms of queries. Those come with getting access to a particular price through its metric identify and querying a spread of metric values, necessarily enforcing pagination in queries.
Those necessities let us create take a look at question patterns according to our wishes. We will use those checks to steadily test our implementation and establish any functionality problems that we will have overpassed. The bottom line is to generate a big sufficient set of metrics to briefly discover any doable issues. To facilitate this, I have arrange a single-node cluster with 1000 keyspaces, each and every containing one desk, and used the Latte Benchmarking Software to run and evaluate the benchmark effects.
Throughout the strategy of writing code for the digital desk adapter and benchmarking each and every intermediate degree of implementation, I have recognized important flaws that result in deficient functionality and a big GC footprint. So, I’m desperate to percentage those findings with you currently.
Discovering #1: Stay in Thoughts Object’s Lifecycles
That is the most straightforward rule of thumb, however it’s nonetheless necessary to stay it in thoughts all the time. In Java, rubbish assortment occurs routinely throughout the life of a program, so there’s no want to deallocate reminiscence manually. On the identical time, failing to liberate gadgets which are now not important may end up in reminiscence leaks. When you find yourself running with an inside part and you notice get started/forestall or upload/take away, which identifies the part’s lifecycle, all the time understand that you wish to have to wash up the assets that you’ve got used.
For instance, when a consumer desires to create a keyspace, a collection of distinctive metrics, such because the choice of pending compactions and so forth, is created accordingly. This set of metrics most effective is smart throughout the life of the keyspace and will have to be launched when the keyspace is dropped. In a different way, the set of metrics will develop, inflicting reminiscence leakage and function degradation.
Discovering #2: Needless Allocations
To start with, assuming that digital tables with metrics could be used rather intensively, I sought after to look what the worth of the reminiscence footprint could be. To get a really feel for this, I used the Cassandra Pressure and prior to now discussed the Latte Benchmark Software to fret my single-node cluster and took some flight recordings the use of Java Venture Regulate (JMC); the use of the “object allocation and promotion” profiling atmosphere was once sufficient to seek out main flaws within the implementation.
The next reasonably evident flaws briefly changed into obvious:
- Needless auxiliary gadgets on requests: Each and every time a brand new subset of metrics was once asked, e.g., through calling the
getCounters()approach, a brand new example of a TreeMap was once created. This is a part of the MetricsRegistry implementation, which isn’t smartly fitted to being within the hotpath in our case. A brand new map for each and every question is an excessively dear strategy to fetch the metrics, and it’s higher to keep away from it; - Needless conversions and buffer allocations: At the one hand, we’ve got metric names and metric cases saved as strings or gadgets at the JVM heap, and however, we’ve got a work of the similar information represented in binary structure for additional comparability (as a DecoratedKey and/or DataRange through the rule of thumb of the digital desk API we use). It seems that no longer growing and, in flip, no longer allocating ByteBuffers, a DecoratedKey for each and every metric for the sake of filtering effects and generating the output offers us functionality advantages, a slightly evident commentary however nonetheless value bringing up.
In consequence, through getting rid of those flaws, I used to be ready to extend throughput through virtually ~ +10% over the former model.
Discovering #3: Lazy Computation of Values
Some other somewhat easy and easy-to-implement method that reduces the reminiscence required for computations and decreases the GC force, thereby improving general potency, gave us ~140% of the entire throughput building up.
You need to lengthen the calculation of pricy metric values till it is completely important. This manner is each easy and sensible to enforce. To start with, use the minimal important parameters, such because the metric kind and/or identify, to clear out as a lot information as conceivable. Compute the metric price most effective after this preliminary filtering step, in particular to build a desk row for the output consequence.
This technique is acceptable to metric sorts corresponding to com.codahale.metrics.Histogram and com.codahale.metrics.Timer. Those sorts are being introduced as a number of other Reservoirs categories for processing their saved measurements. For instance, configuring a metric with com.codahale.metrics.SlidingTimeWindowReservoir comes to a sliding window mechanism that most effective assists in keeping measurements from the remaining N seconds.
It’s also obviously visual in Java Venture Regulate when profiling:
Stack Hint Depend Proportion
void o.a.c.m.DecayingEstimatedHistogramReservoir$AbstractSnapshot.<init>(DecayingEstimatedHistogramReservoir) 15323 8,79 %
void o.a.c.m.DecayingEstimatedHistogramReservoir$EstimatedHistogramReservoirSnapshot.<init>(DecayingEstimatedHistogramReservoir) 14036 8,05 %
Snapshot o.a.c.m.DecayingEstimatedHistogramReservoir.getSnapshot() 14036 8,05 %
Snapshot com.codahale.metrics.Histogram.getSnapshot() 14036 8,05 %
String o.a.c.m.CassandraMetricsRegistry.getValueAsString(Metric) 14036 8,05 %
String org.apache.cassandra.db.digital.fashion.MetricRow.price() 14036 8,05 %
void org.apache.cassandra.db.digital.fashion.MetricRowWalker.visitRow(MetricRow, RowWalker$RowMetadataVisitor) 14036 8,05 %Discovering #4: Improving Seek Potency
As soon as all of the teething issues and bottlenecks had been triumph over, we will be able to get started fascinated about the metrics set itself to give a boost to the question execution time and general throughput.
Metrics within the utility are tied to a few inside part that must be monitored. This connection is vital to environment friendly seek, and so our methods for organizing metrics could be:
- Department of metrics: We will categorize all of the set of metrics into other MetricRegisters. Each and every MetricRegister corresponds to a particular metric crew and, in flip, reduces the iteration prices;
- Incorporating crew identify: We will come with the metric crew identify without delay throughout the metric’s identify. This technique complements the potency of metric filtering and the usage of
hashCode()at the metric identify, each and every time we want to establish the metric crew turns into redundant;
Even supposing the latter offers us a horny excellent functionality development, we will be able to in fact use each.
Discovering #5: Parallel Processing Is not Quicker
Apache Cassandra can host a lot of tables and keyspaces, leading to a lot of corresponding metrics. Successfully responding to consumer queries on this context calls for filtering this massive set of metrics. Crucial attention this is the selection between sequential and parallel processing, which the Java Movement API supplies:
// true - parallel processing, false - sequential processing
StreamSupport.movement(information.spliterator(), true)
.map(metric -> makeRow(metric, columnFilter))
.clear out(row -> keyRange.comprises(row.key()))
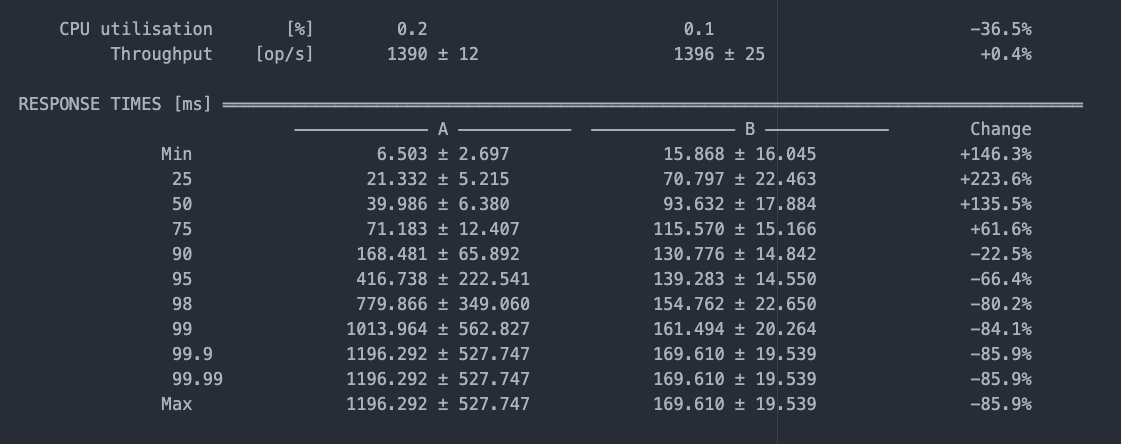
.forEach(row -> map.put(row.getKey(), row));Imagine the benchmark instance beneath, which compares parallel (A) and sequential (B) processing of metrics. The effects display an identical throughput for each strategies. On the other hand, whilst parallel processing yields quicker first effects, sequential processing supplies extra balance and places much less force on GC.
In consequence, sequential processing is extra appropriate for querying a digital desk through metric identify to retrieve a unmarried metric price. This manner is easily fitted to the necessities of exterior tracking methods. However, parallel processing is extra appropriate for vary queries initiated through customers.
Discovering #6: Solidify Design Type
The MetricRegistry retail outlets metrics in a map, with each and every metric’s distinctive identifier appearing because the map key. You need to understand that most of these metrics are native to the node being monitored. In the meantime, the Digital Desk API supplies a big number of techniques to create digital desk metadata, permitting you to build a number one key composed of a number of partition keys and nil or extra clustering keys.
On the other hand, for the aim of disclosing metrics, this manner could be extra complicated than important. If we simplify the construction through assuming that the main key and partition key are similar and that the metrics digital desk does no longer have clustering keys, we will be able to considerably give a boost to the method of retrieving metric values through identify. This system is far quicker the use of a map once we want to question through key than iterating in the course of the Assortment interface, which is the overall way to exposing the interior information as digital tables.
Demo
Because of most of these enhancements, the interior metrics saved within the MetricRegistry are to be had below a brand new digital system_metrics keyspace, permitting you to question them in a high-performance approach.
The snippet beneath presentations the commonest utilization instance:
Conclusion
In abstract, this adventure into Apache Cassandra’s metrics device, in particular in the course of the lens of Dropwizard Metrics and the digital desk API, unearths a number of insights and methods for optimizing functionality and potency for a selected implementation, corresponding to lazy computation of metric values, bettering seek potency and filtering of a giant metric set, and offers benchmark effects evaluating sequential vs. parallel processing of the metric set for the wishes of a CQL question.